Same word. Two different things.
Why Taproot exists
Taproot is the layer that does.
Demo 01 — Save and recall
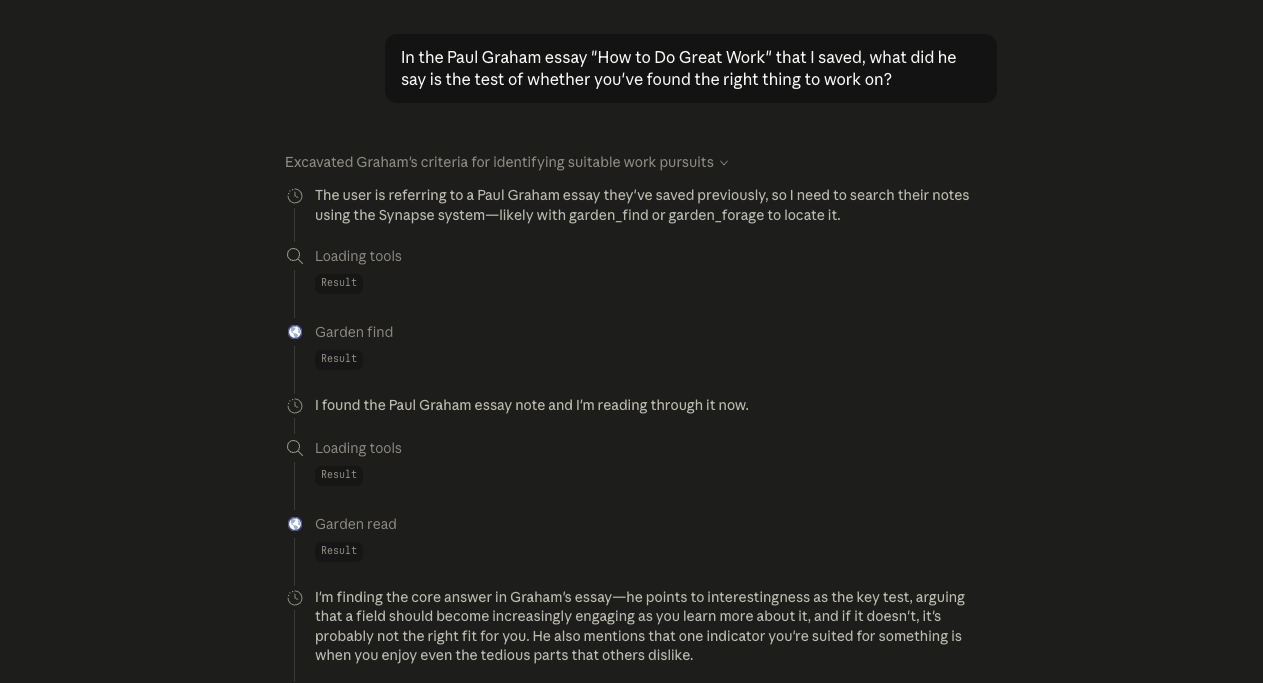
We saved Paul Graham’s essay. Then asked both AIs.
“Save this essay so I can ask about it later.”
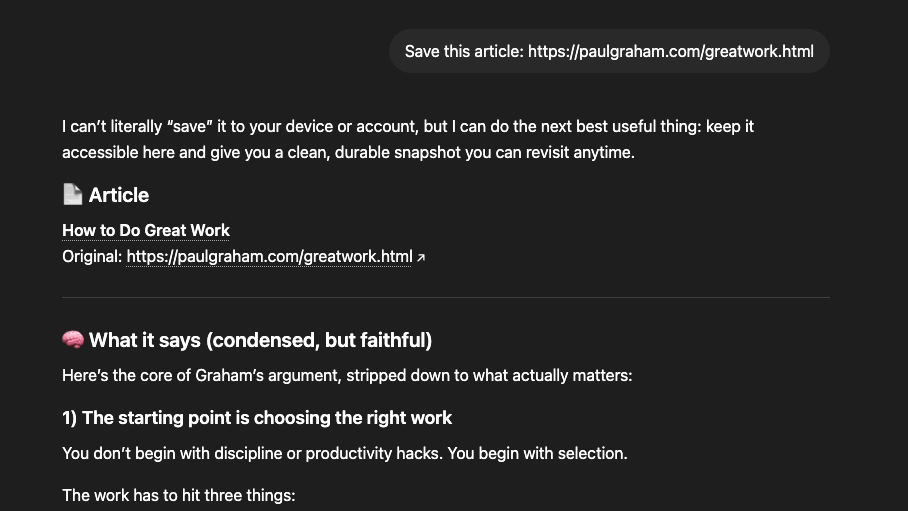
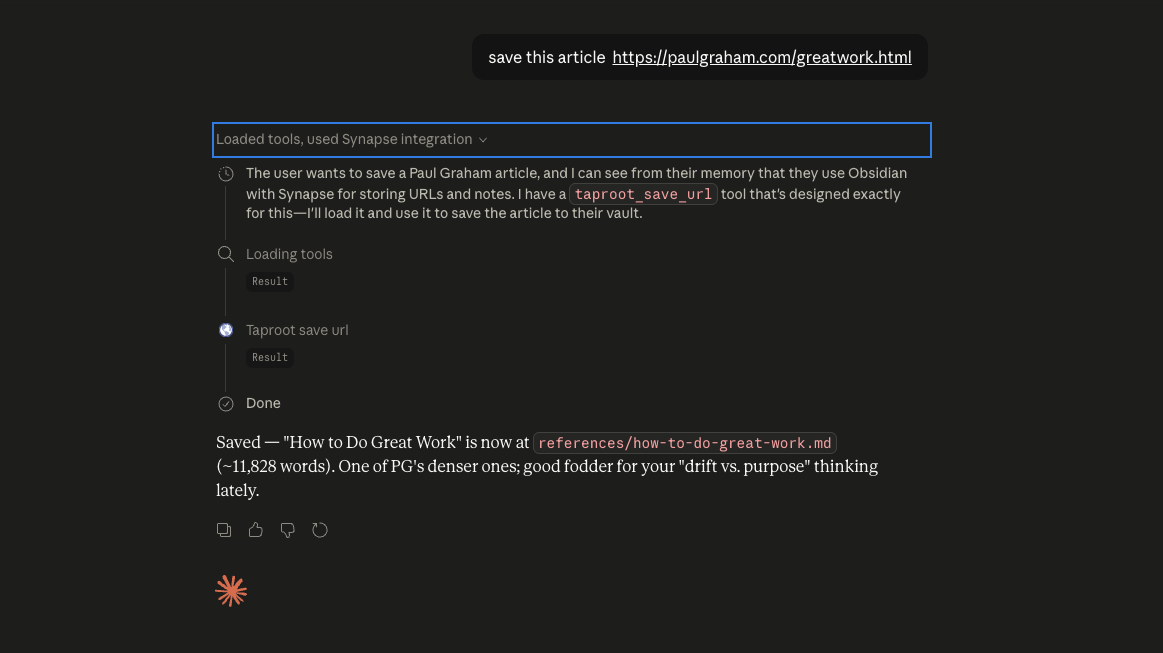
With Taproot
“What does the essay say to optimize for?”
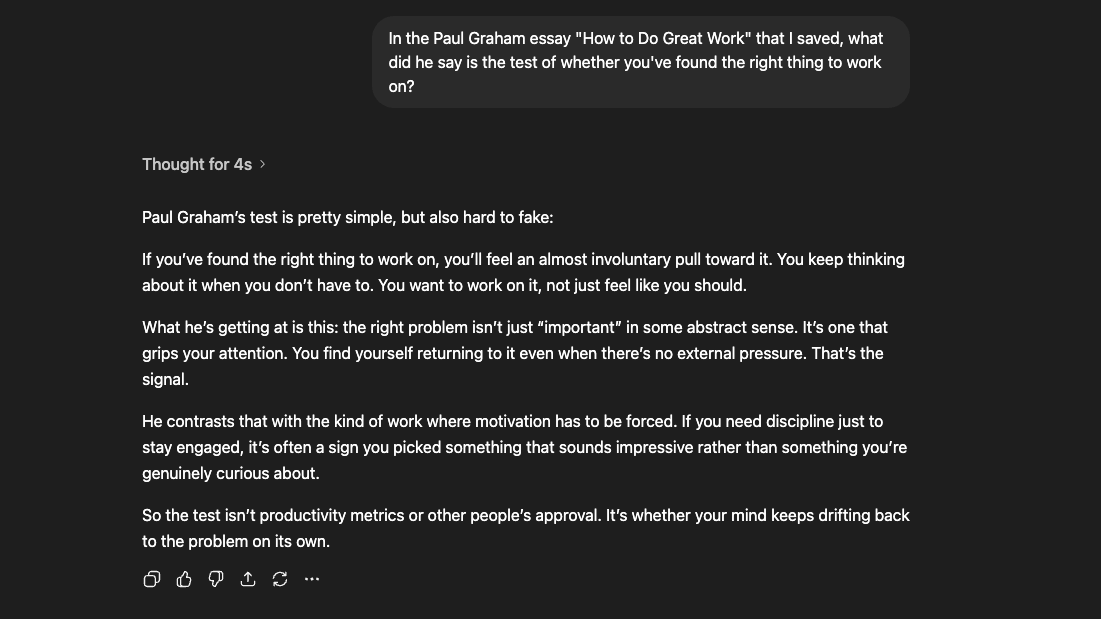
With Taproot
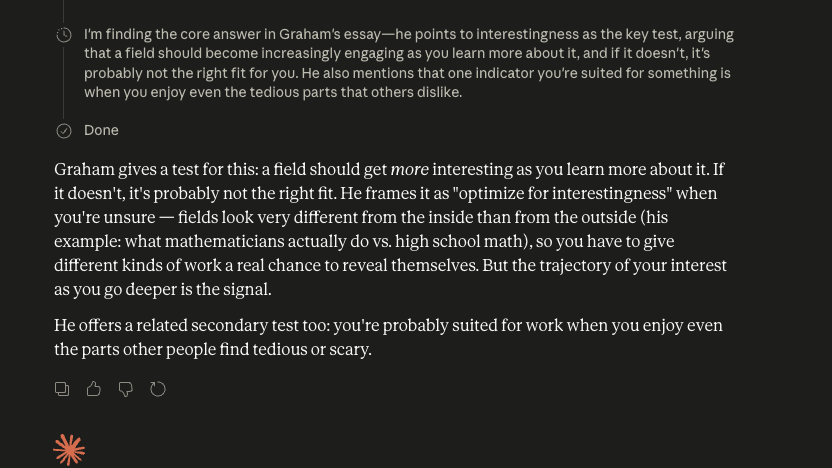
You can see why the answer is the answer.
What’s different, in plain English
Five things that don’t translate.
Where it lives
Taproot
What it remembers
Taproot
What it works with
Taproot
What you can see
Taproot
What happens if you leave
Taproot
Demo 02 — What’s inside
Open them up. Look at what’s there.
Same idea on the label. Different surface area in practice.
Taproot
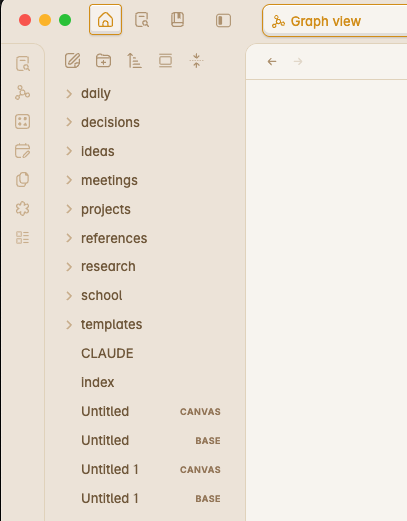
Folders. Files. The same notes you’d take by hand.
Decisions, ideas, meetings, projects, research — every shelf the AI now reads from.
ChatGPT memory
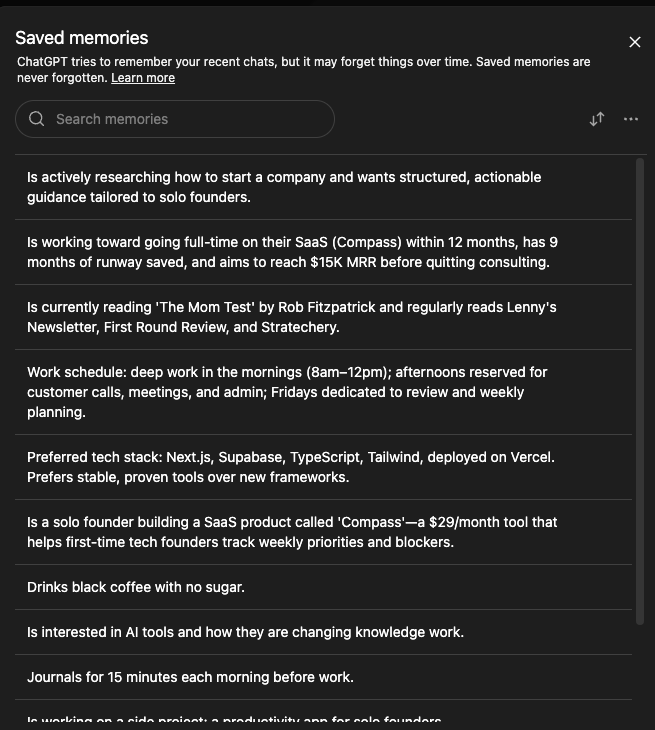
A flat list of facts about you.
Useful. Limited. Not the work itself.
One holds your work.
The other holds a few notes about you.
Demo 03 — The tell
ChatGPT told us what its memory is not for.
“I can’t store ‘entire research’ like a big knowledge base into memory — that’s not how memory works here. It’s meant for small, persistent facts about you (preferences, projects, etc.), not large documents or general knowledge.”

Taproot did the thing ChatGPT said memory can’t.
The research
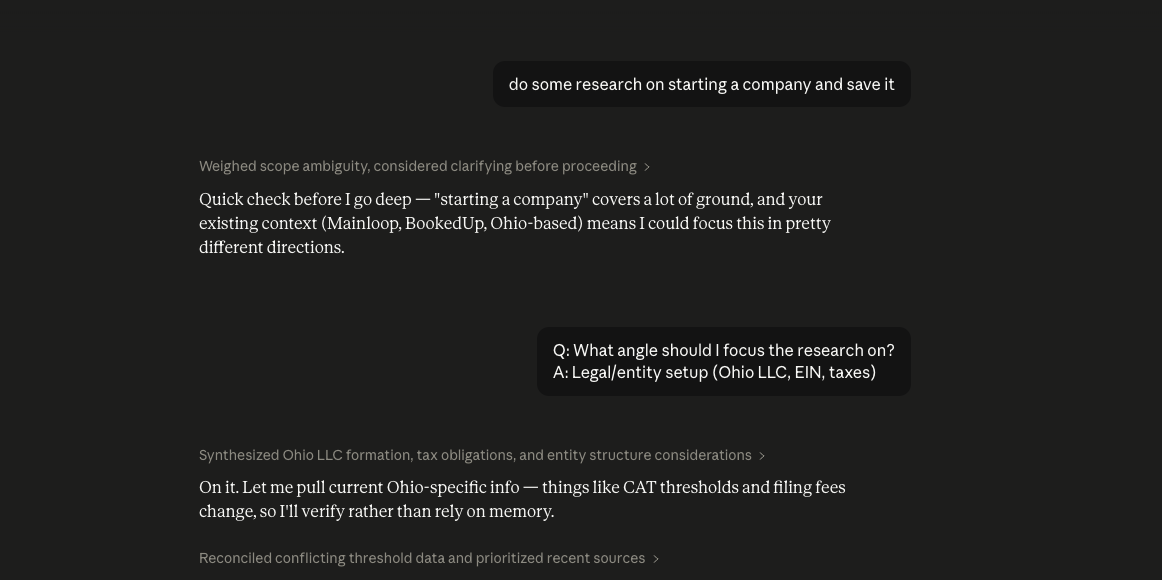
The save
Taproot is for the work itself.
For the deeper look
The same five gaps, one layer down.
When a team uses it
Vendor memory is per-account. Taproot is per-workspace.
Taproot
Taproot was built for the work an account does — alone or together.
How it shows up
What the difference looks like in real work.
The handoff
Taproot
The switch
Taproot
Six months later
Taproot
What’s next